Data Transformation Tool: BryteFlow Blend
Data Transformation Tool with a Drag and Drop Interface

Data Transformation that is easy and automated
Data transformation is simple with BryteFlow Blend. BryteFlow Blend is a data transformation tool that transforms, remodels, schedules, and merges data from multiple sources in real-time on platforms like Amazon Redshift, Amazon S3, PostgreSQL and Snowflake. The data transformation tool provides quick time to value, reducing deployment time by as much as 90%. How BryteFlow works
Automate your ETL Process and Data Transformation
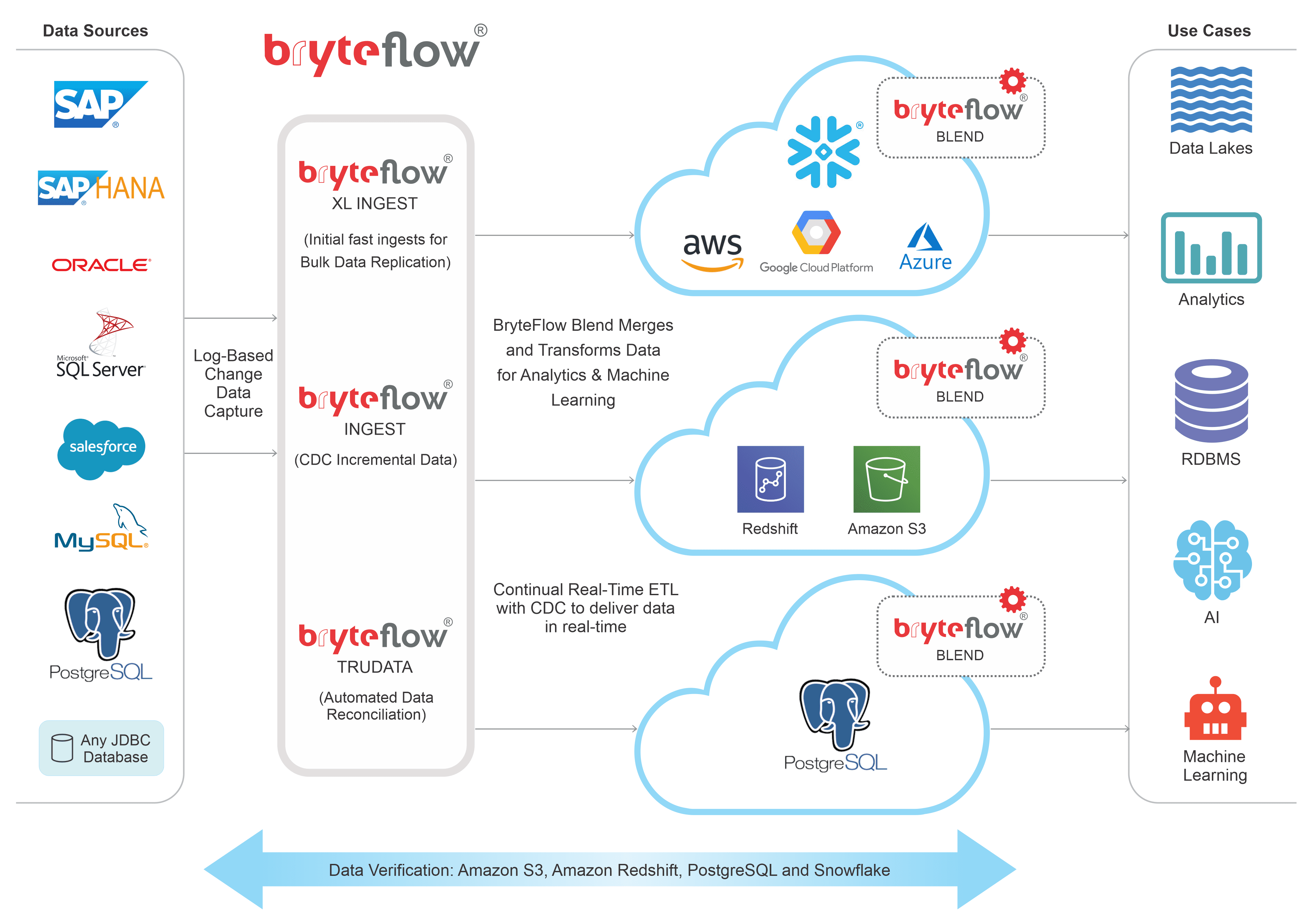
Your ETL process gets completely automated whether it is real-time data extraction and replication by BryteFlow Ingest or the data transformation by BryteFlow Blend. This data transformation tool sidesteps laborious PySpark coding to prepare data with simple SQL and has an intuitive drag-and-drop interface for complete end-to-end workflows. Replicate data from multiple sources like SAP, Oracle, SQL Server, Postgres, MySQL etc., merge datasets, transform data and get ready-to-use data in real-time for Analytics, AI, and ML with BryteFlow’s ETL tools. BryteFlow also has a Sap ETL tool that extracts data directly from SAP applications. About AWS ETL
Build a Reliable ETL Pipeline with our Data Transformation Tool
- BryteFlow Blend Integrates seamlessly with BryteFlow Ingest, our data ingestion tool.
- Data transformation tool merges multi-source data from legacy databases, data from sensors and devices and application data, and transforms the data using simple SQL.
- Ideal for ETL flows on Redshift, Amazon S3, PostgreSQL and Snowflake, incorporating best practices for each.
- BryteFlow’s ETL software uses log-based CDC (Change Data Capture) for the ETL process.
- The ETL tools extract, transform and load data automatically and provide analytics-ready data assets. How to load terabytes of data to Snowflake fast
- BryteFlow ETL creates a data-as-a-service environment, where business users can self-serve and access data for fast insights without tech dependency.
- Data transformation tool produces analytics-ready data assets for Analytics, AI, and ML.
- Automated data reconciliation with BryteFlow TruData, no unpleasant instances of missing data. How to Manage Data Quality (The Case for DQM)
ETL Process Architecture
Automated, Real-time
Data Transformation Software
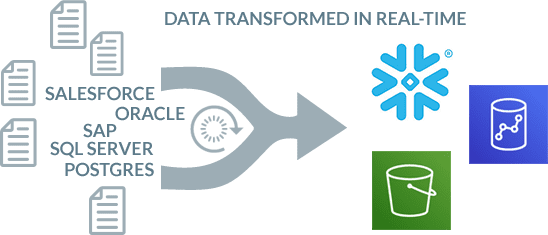
Transform and merge data from multiple sources in real-time.
Remodel, transform, schedule and merge data from multiple sources like transactional databases, applications, and sensors, and break down data silos in real-time or as the raw data is ingested. BryteFlow Blend is a data transformation tool for ETL that transforms data in Amazon S3, Redshift and Snowflake (Snowflake on AWS, Azure and other platforms).
Successful Data Ingestion (What You Need to Know)

Data Transformation on AWS made easy.
Run and schedule complex Hadoop/SPARK data transformations by simply using SQL. BryteFlow provides an Enterprise grade Data Preparation workbench. You can easily create and manage multiple folders, jobs, and dependencies. Categorize data easily into different levels of security classifications and maturity – from raw data through to highly curated data marts. Compare BryteFlow with AWS DMS
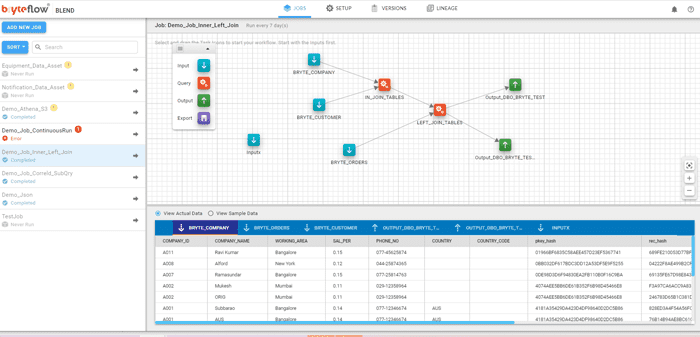
User-friendly Drag and Drop Interface for Data Transformation.
Run all data preparation and workflows as an end-to-end process. Select source, destination, and schedule time as per convenience. The job you create is represented by an interactive drag and drop workflow diagram with tasks you can add and connect as you go. This visual representation adds clarity and flexibility to the data transformation process. Get a Free Trial of BryteFlow
Flexibility in consumption of data – use the BI tools of your choice.
BryteFlow Blend allows you to consume the data with the tools of your choice including Amazon Athena for adhoc queries in S3, Redshift Spectrum for joining with data on Redshift, and your favorite data visualization tools for dashboards in Snowflake and Redshift. You can also copy data to Aurora for your web applications or marketing initiatives. Amazon Athena vs Redshift Spectrum

Smart Partitioning and Compression for fast, high performance data transformation.
BryteFlow Blend uses smart partitioning techniques and compression of data to deliver super-fast performance. Data can be transformed in increments rather than at one go so you get to use your data that much faster.
How to Manage Data Quality (The Case for DQM)

The ETL software creates a Data-as-a-Service environment, where business users can self-serve.
BryteFlow Blend along with BryteFlow Ingest creates a self-service ETL platform for data transformation and data ingestion. The tools are completely automated, and you can save on DBA and developer’s time since your business users can run the ETL software themselves, no expert resources needed!

Integrates with BryteFlow Ingest to run data transformation jobs automatically.
You can configure BryteFlow Blend for seamless integration with BryteFlow Ingest so it will automatically get triggered and get activated when new data is extracted to BryteFlow Ingest. The data transformation process is triggered automatically.

Data Transformation with Automated Full Metadata and Data Lineage.
All data assets have automated metadata and data lineage. This helps in knowing from where your data originated, what data it is and where it is stored.

ETL Process with Automatic Catch-up from Network Dropout.
No need to panic if your data transformation is interrupted by a power outage or a similar situation. You can simply pick up where you left off – automatically. In the event of a system outage or lost connectivity, BryteFlow Blend features an automated catch-up mode, so you don’t have to check or start afresh with the ETL process. Get a Free Trial of BryteFlow