
With some the planet’s most important interactions running on them, relational application and database environments like Oracle, Microsoft and SAP contain large amounts of valuable enterprise data. However, the true value in this data is rarely uncovered because it is difficult to extract, store and enable end user access for analytics purposes. In this note, I will talk about some of the key challenges encountered by enterprises as they try to liberate their data. My primary aim for this note is to stimulate internal thought and discussion within internal enterprise teams who are about to commence a project. By being aware of some of these challenges and roadblocks early, you may be able to factor these issues into planning processes, technology and vendor discussions.
This will be followed by another note where I will discuss approaches and solutions using off-the-shelf technologies like BryteFlow software with Amazon S3 and AWS Big Data Infrastructure.
Adverse application impact
The possibility of adverse application impact is the single greatest barrier most enterprises face when it comes to getting analytical value out of their application data. Commonly used ETL processes like bulk extracts or triggers have a costly I/O impact and threaten primary transactional workloads. A large retailer, for instance, would not want their point of sale system to crash because an analyst wanted to pull out key tables out during peak hour. For business analysts and other data consumers, this means that:
- They can never get their hands on all the raw data they are after – the size of the ETL job would simply be too large.
- They put a lot of load on their source system to pull the data
High Data Volumes
Powering large applications for thousands or millions of users generates data at both high volume and high velocity. This makes it difficult for enterprises to retain and store all the raw data from large application environments in their existing Data Warehouse or Analytics platform due to:
- The high cost of data storage
- Performance and scale limitations
As a result, ETL jobs are configured to delete or filter most of the data that does not have an existing business use case, before it is loaded into Data Warehouses or other central data repositories. This filtering activity:
- Prohibits experimental and discovery analytics, the entire point of which is to find new relationships in data.
- Delays time to insight for any reports that require access to new data fields or data sets – Modifying or changing ETL processes can be a lengthy process requiring careful impact analysis and planning.
Hadoop platform limitations for Application Data
With opportunities to lower cost of storage and perform advanced data analytics, enterprises are are looking for ways to deliver their application data to Hadoop based platforms. However, these platforms are not optimized to ingest or process high volume transactional data from relational application database environments.
Absence of Enterprise grade off-the-shelf tools
Most ETL tools for relational data are designed to replicate tables between databases – they are not optimized for ingestion into HDFS based file systems or object stores. This leaves enterprises with little option but to hand code ETL solutions or stitch together multiple open source components where available. As accurate and timely delivery of data is the most important success factor for any analytics project, this approach creates a significant risk. Even where hand coded or self hacked solutions are effective, they require extensive internal support and often struggle to scale up when data volumes increase.
Difficulties streaming data
Object stores and HDFS based systems store data in file format under a folder structure, not as tables in a schema. This creates numerous challenges when data from application tables is being streamed on a continuous basis. Each new record insert, update or delete from the source database comes through as a separate file. For transactional systems with high activity, data from a single table can end up being proliferated across thousands of different files, making it extremely difficult for users to interact with the data.
Here is a simple example to illustrate this concept further. Let us imagine the following table at source, one that has just been replicated in its entirety to a HDFS file system or an object store:
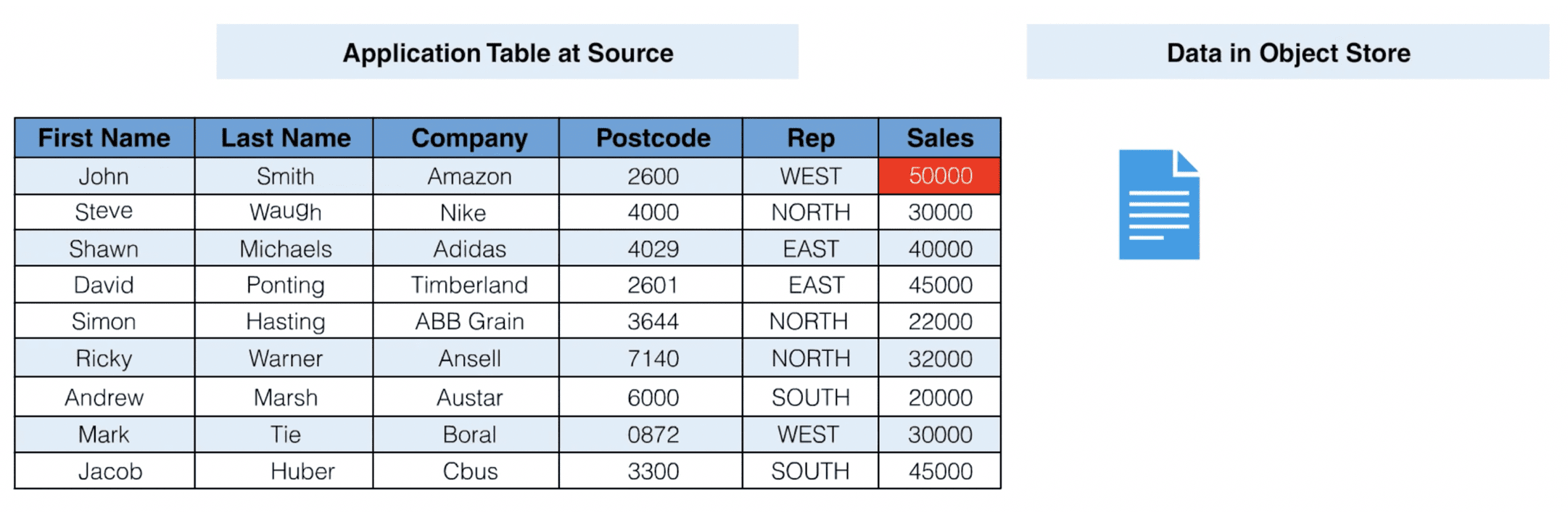
As you can see, the table will come through as a single file in an HDFS object store. After this initial data extract, the last row of the table is updated at the source database. Customer Jacob Huber now has a new post code and an updated sales amount.
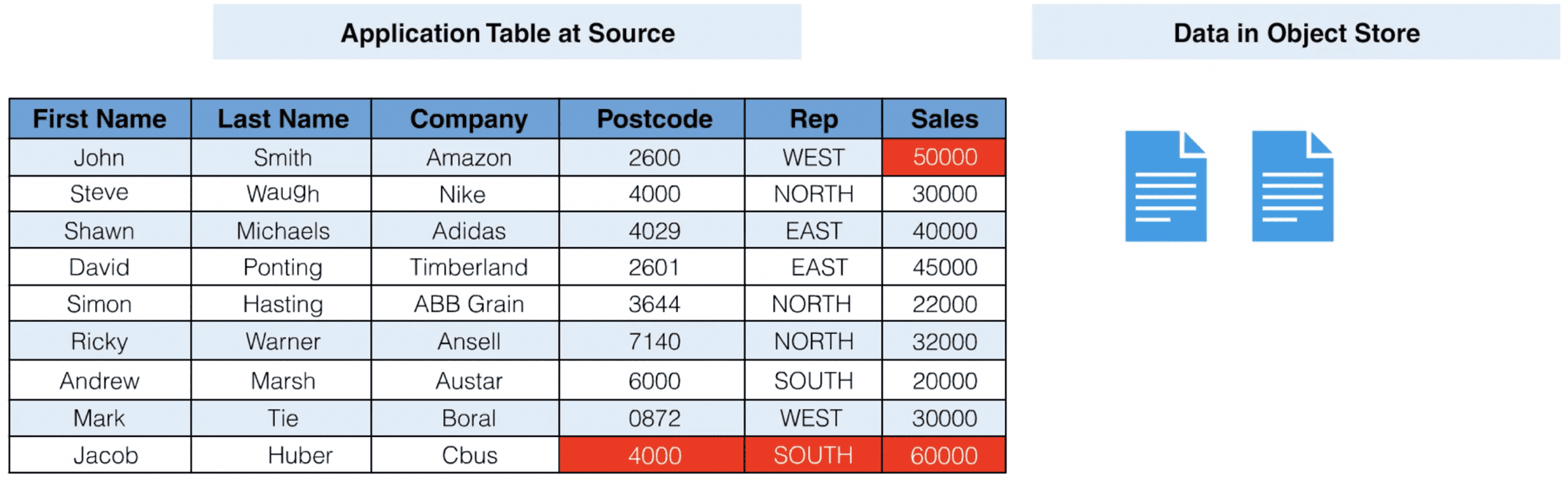
A new file is generated which contains information about the change that has just taken place and data in the table is now distributed across two separate files in the object store. The first file contains all the contents of the table as it was first loaded, and the second file contains an update statement. In order to understand what the new table looks like, an analytics consumer would need to write ETL logic to merge the update statement into the initial load file.
These challenges are compounded when dealing with transactional systems that have a high volume of changes. Hadoop distributions are not equipped to absorb this style of relational ETL workload (record insert, update and delete commits). As a result, there is a high node to workload ratio, which can result in excessive ETL infrastructure costs.
Legacy Data Structures
Freeing data from application databases can require dealing with legacy application data types, undocumented structural semantics and un-partitioned tables.
Undocumented structural semantics are particularly challenging when there are applications like SAP which have complex table relationships. For example – an SAP invoice object in the application could have its data distributed across 10 different database tables. If the relationship between the application data and underlying database tables is not well understood, analytics users will find it very difficult to consume the data.
Un-partitioned tables create serious problems once they start becoming excessively large in size. In particular, there is high source system impact for an initial extract of such a table. If the initial extract is initiated from a production or live system, the source database will need to hold a static snapshot of the table against a backdrop of high change volume, rapidly escalating query size and system overhead. Even if the table can be extracted, there are further challenges:
- The extraction process can take days or weeks.
- If the extract process fails or is interrupted for any reason, the entire job will have to start from scratch (lack of partitioning effects the ability to recover parts of the table that have already been extracted).
Data Security
Application databases often contain sensitive or confidential data fields that are well protected within the application environment with appropriate roles, view permissions and policies. When data needs to extracted from these environments, enterprises need to find ways to address various concerns including:
- Data encryption in transit and rest
- Data Masking and Tokenization
- Replication of the app level security roles and policies



