Real-Time, Automated
Data Replication Software
BryteFlow Data Replication
BryteFlow for SAP BryteFlow for Oracle BryteFlow for SQL Server BryteFlow for PostgreSQL BryteFlow for MySQLReplication Platforms
Amazon S3 Amazon Redshift Snowflake SQL Server Azure Synapse Analytics ADLS Gen2 Apache Kafka Google BigQuery PostgreSQL Databricks Teradata SingleStoreReplication Software for Easy Enterprise Data Integration
BryteFlow is a no-code data replication software that replicates your data using CDC from transactional sources like SAP, Oracle, SQL Server, MySQL and PostgreSQL to popular platforms like AWS, Azure, SQL Server, BigQuery, PostgreSQL, Snowflake, SingleStore, Teradata, Databricks and Kafka in real-time, providing ready to use data on the destination. Our data replication software is automated, GUI driven, self-service and offers out-of- the-box support for bulk data. Change Data Capture and CDC Automation
BryteFlow as an alternative to Matillion and Fivetran for SQL Server to Snowflake Migration
Super-fast Data Replication Tool: 6x fasterthan GoldenGate
Super-fast Data Replication Tool: 6x faster than GoldenGate Our replication tool BryteFlow Ingest transfers petabytes of data in minutes – approx. 1,000,000 rows in 30 seconds. BryteFlow is fast to deploy and you can get delivery of data within 2 weeks as opposed to months for our competitors.
Data pipelines and reasons to automate them
How to Manage Data Quality (The Case for DQM)
Aurora Postgres and How to Setup Up Logical Replication
Zero-ETL, New Kid on the Block?
Successful Data Ingestion (What You Need to Know)
BryteFlow Data Replication Tool: Technical Architecture
This technical diagram explains how BryteFlow replicates and transforms data.
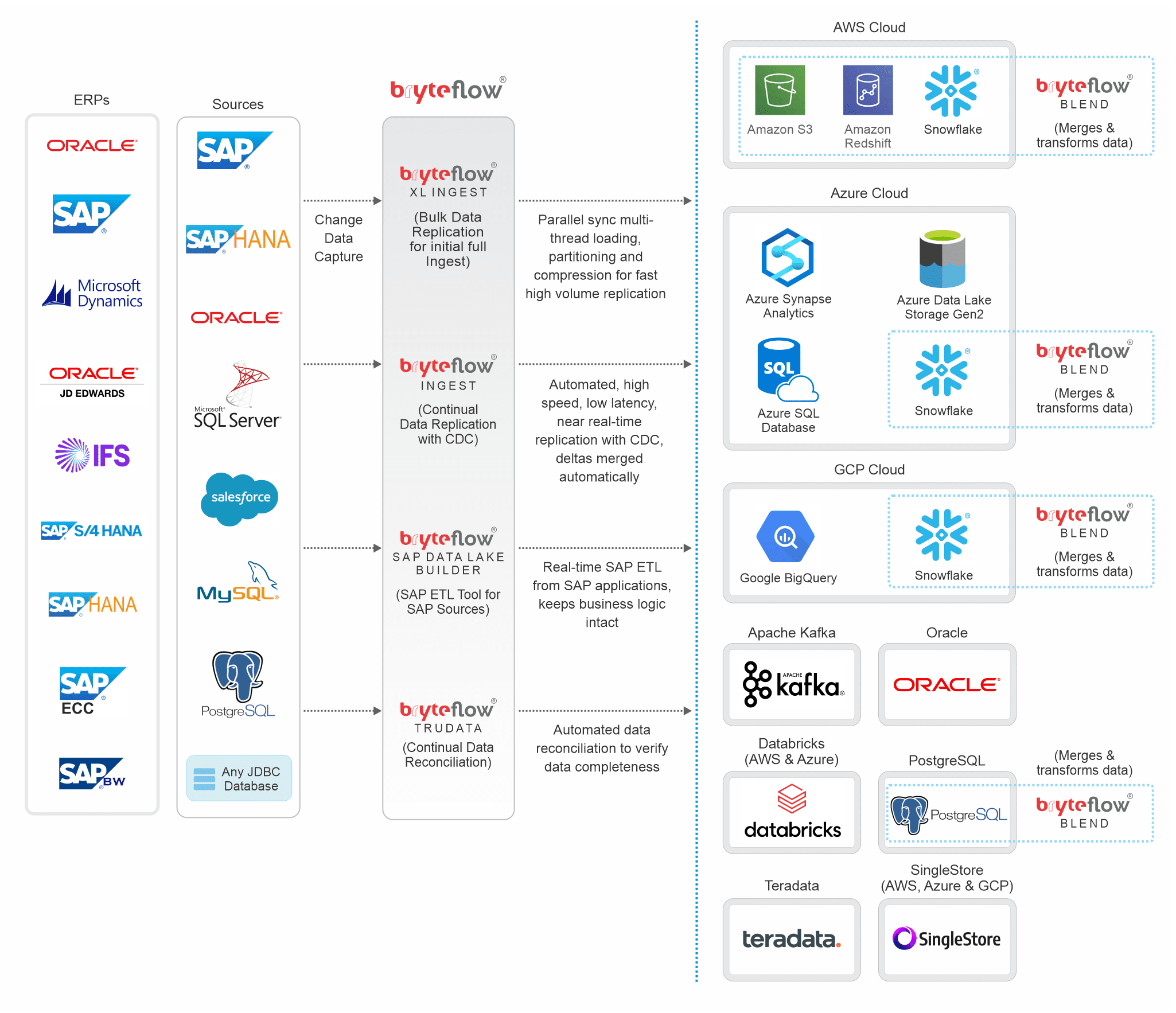
Data Replication Tool Highlights
- Support for SAP ETL- extracts data from SAP at application level or database level with SAP Data Lake Builder
- Our data replication tool BryteFlow Ingest uses Change Data Capture (CDC) to capture deltas. More on Oracle CDC
- ETL data on Snowflake, S3, Redshift and PostgreSQL in real-time without coding. BryteFlow Blend does the data transformation
- Incremental changes are merged automatically with initial data, for continual sync with source. More on SQL Server CDC
- No code data replication tool with a visual, easy-to-use UI, makes data available in almost real-time for Analytics and ML
- Supports bulk loading of data with XL Ingest using multi-threaded parallel loading, partitioning and compression
Data Migration 101 (Process, Strategies and Tools)
- Replication software has extremely high throughput – 6x faster than GoldenGate, approx. 1,000,000 rows in 30 seconds
- Our data replication software automates DDL creation on the destination with best practices for performance
- Data is time-series and you can get a history of every transaction Data replication tool provides high availability out-of-the-box
- Get ready-to-use data on cloud platforms like S3, Redshift, Snowflake, Azure Synapse, ADLS Gen2, SQL Server, Kafka, PostgreSQL, BigQuery, Teradata and Databricks.
- Automated data reconciliation with BryteFlow TruData to verify data completeness How to Manage Data Quality
- Highly resilient, replication provides Automated Network Catch-up in case of power or network outage
BryteFlow Data Replication Software Features
Whether it is extracting and replicating SAP data, fastest ever replication for Oracle, SQL Server, MySQL or Postgres, BryteFlow handles it in real-time, and automates every process. For extracting SAP data and ingesting it directly from source systems, we also have the unique SAP Data Lake Builder.

Real-time, No Code Replication Software
BryteFlow replicates data from hundreds of sources automatically in real-time. It has a user-friendly point-and-click interface that can be used easily by business users. There is no coding for any process, including data extraction, merging, masking, or type 2 history. No external integration with third party tools like Apache Hudi is required. Your data is ready to use at destination almost immediately.
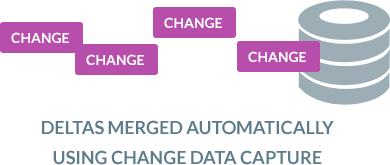
Merges changes automatically with data using log-based CDC
BryteFlow Ingest continuously merges new change files with existing data automatically using log-based CDC and other CDC options so your data is automatically updated and synced with source. BryteFlow CDC ensures there is no impact on source systems while enabling very high throughput.
Learn more about Oracle CDC, SQL Server CDC and Postgres CDC
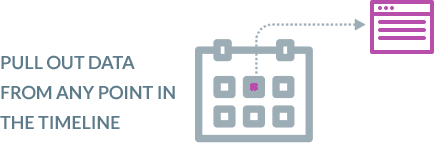
Replication software that preserves a history of every transaction with time-series data
BryteFlow delivers time-series data for easy point-in-time analytics. You get out-of-the-box options to maintain the full history of every transaction with options for automated data archiving. This versioning feature is great for historical and predictive trend analysis.

Automated DDL creation on the destination with best practices for performance
BryteFlow automates DDL (Data Definition Language) and creates tables automatically on the destination. You never need to waste your time in tedious prepping of data.
Source to Target Mapping Guide
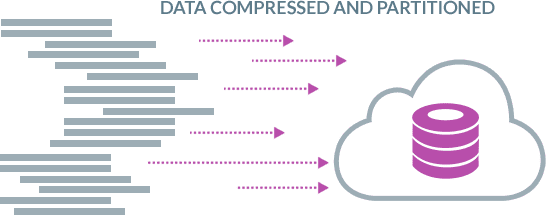
Bulk Loads with Smart Partitioning and Parallel Loading
When you are replicating bulk loads BryteFlow XL Ingest is used for the initial full ingest of data. It uses smart partitioning technology to partition the data and parallel sync functionality to bulk load data in parallel threads. After the initial full ingest, BryteFlow Ingest uses CDC to continuously and automatically merge the deltas to sync with source.
Aurora Postgres and How to Setup Up Logical Replication
BryteFlow offers ETL/ ELT on Snowflake, Amazon Redshift and Amazon S3 in real-time
BryteFlow Blend merges and transforms multi-source data extracted by BryteFlow Ingest as part of the ELT process. BryteFlow Ingest loads data from the sources in real-time to Snowflake and Amazon Redshift where BrtyteFlow Blend merges, transforms and provides data in ready-to-use formats like Parquet, ORC etc., Alternatively it can also provide ETL on AWS by extracting and transforming data on S3 and then loading modeled data to Snowflake and Redshift.
BryteFlow ETL / ELT on Snowflake

Replication tool provides Data Type Conversions out of the box
BryteFlow replication software provides a range of data conversions out of the box including Typecasting and GUID data type conversion to ensure that your data is ready for analytical consumption or for Machine Learning.
GoldenGate CDC and a better alternative

Fast Data Replication Tool: 6x faster than GoldenGate
Our data replication tool replicates data at an approx. speed of a million rows in 30 seconds. The replication software is at least 6x faster than GoldenGate and faster than other competitors. It has the highest throughput for Oracle replication. BryteFlow can be deployed in one day and time to delivery of data is just 2 weeks.
Oracle Replication in real-time, step by step

Data Replication with Automated Data Reconciliation
BryteFlow TruData our data reconciliation software integrates with the BryteFlow replication software to provide automated data validation. It checks data for completeness using row counts and columns checksum and provides alerts for missing or incomplete data.
SQL Server to Snowflake in 4 Easy Steps

The replication software has high availability and resiliency with Automated Network Catchup
If there is a power or network outage, BryteFlow has an automated catch-up mode. The process starts up automatically from where it had stopped after normal conditions are restored.
Debezium CDC Explained and a Great Alternative CDC Tool

Dashboard to monitor data ingestion and transform instances easily
The BryteFlow ControlRoom integrates seamlessly with our replication software to display the status of various Ingest and Blend instances so you can track the processes that are happening easily.
Zero-ETL, New Kid on the Block?

BryteFlow SAP Data Lake Builder – Unique SAP data replication tool to extract SAP data at application level
The BryteFlow SAP Data Lake Builder connects to SAP at the Application level. It gets data exposed via SAP BW ODP Extractors or CDS Views as OData Services to build the Data Lake. It replicates data from SAP systems like ECC, HANA, S/4HANA and SAP Data Services. It carries over SAP application logic so it does not have to be rebuilt on destination, saving both – effort and time.
BryteFlow SAP Data Lake Builder
Integrations
Sources
Source databases and applications
BryteFlow supports a wide range of data sources including relational databases, cluster, cloud, flat files and streaming data sources. We can easily add more sources if required. Let us know if you need another source added, we’ll be happy to oblige.
SAP
SQL Server
MySQL
MariaDB

Amazon Aurora

SAP HANA
Oracle
Salesforce

PostgreSQL

Any JDBC Database
Destinations
BryteFlow replicates your data across a large range of platforms.

Amazon S3

Amazon Redshift

Amazon Aurora

Amazon Kinesis
SQL Server

Azure SQL DB
Azure Synapse Analytics

Azure Data Lake Gen2

Snowflake
Oracle
Google BigQuery
Apache Kafka
PostgreSQL
Databricks
