
Data Lakes are used to store all the raw data from all enterprise systems, so that access is enabled easily.
In the past Big Data has been synonymous with Hadoop Data Lakes for holding vast amount of structured and unstructured data.
Hadoop Data Lakes were very popular as the databases and analytical appliances could not scale for the large amounts of data and unstructured data. Hadoop being Open Source was also the reason for this trend as it was much cheaper to use rather than an expensive analytical appliance or database for a Data Lake.
A Hadoop Data lake was constructed by using an army of servers which could provide storage and compute and parallelise the processing.
Unfortunately, Hadoop Data Lakes proved to have the same problem as database technologies. To increase storage, you still had to add extra servers and manage them. Storage and compute was not separated.
Concurrency was another issue with a Hadoop Data Lake just as any database. The more the users, the more the contention for the same resources, making scaling difficult – and hence more servers need to be added to extend compute.
Fast forward to today, with the availability of object stores that leading cloud providers like Amazon Web Services (AWS) provide – are more suited for hosting a Data Lake.
Amazon S3 is the object store available with AWS – an infinitely scalable and cheap platform as low as 1-3cents a Gig per month, for hosting a Data Lake. The power of Hadoop can be used by using an AWS service Amazon Elastic Map Reduce (EMR) whenever compute is required to process data and each user could potentially work on an EMR cluster of the right capacity on demand and shut it when data is not being processed, making this a very attractive platform for hosting a Data Lake.
More data does not equate to more servers, Amazon S3 scales automatically and cold data can also be archived to Amazon Glacier making it even cheaper to host the Data Lake.
The data is then available in the AWS eco-system, with easy access to various services, the Marketplace with the elasticity and scalability and the ability to experiment frequently and evolve the architecture as business needs evolve, without any upfront costs.
The BryteFlow product suite prepares data from your applications to Amazon S3 automatically using proprietary technology to extract data with low impact on the source and preparing data on Amazon S3 using Amazon EMR, with no coding required.
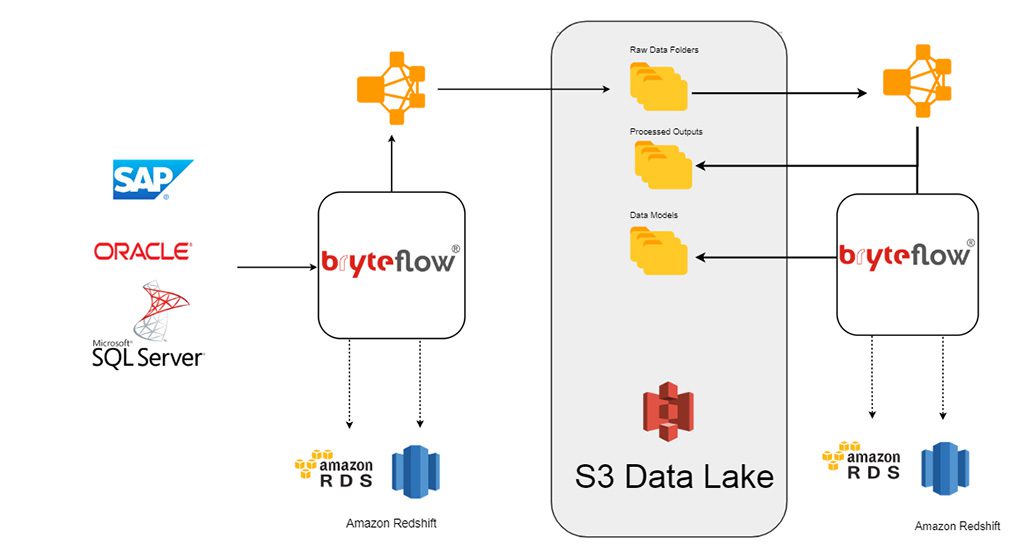
The software prepares the S3 data lake and can also be used to populate the Redshift Data Warehouse if required, at the same time, deploying the best practices which are automated, delivering a modern elastic data platform for a data driven organisation.



